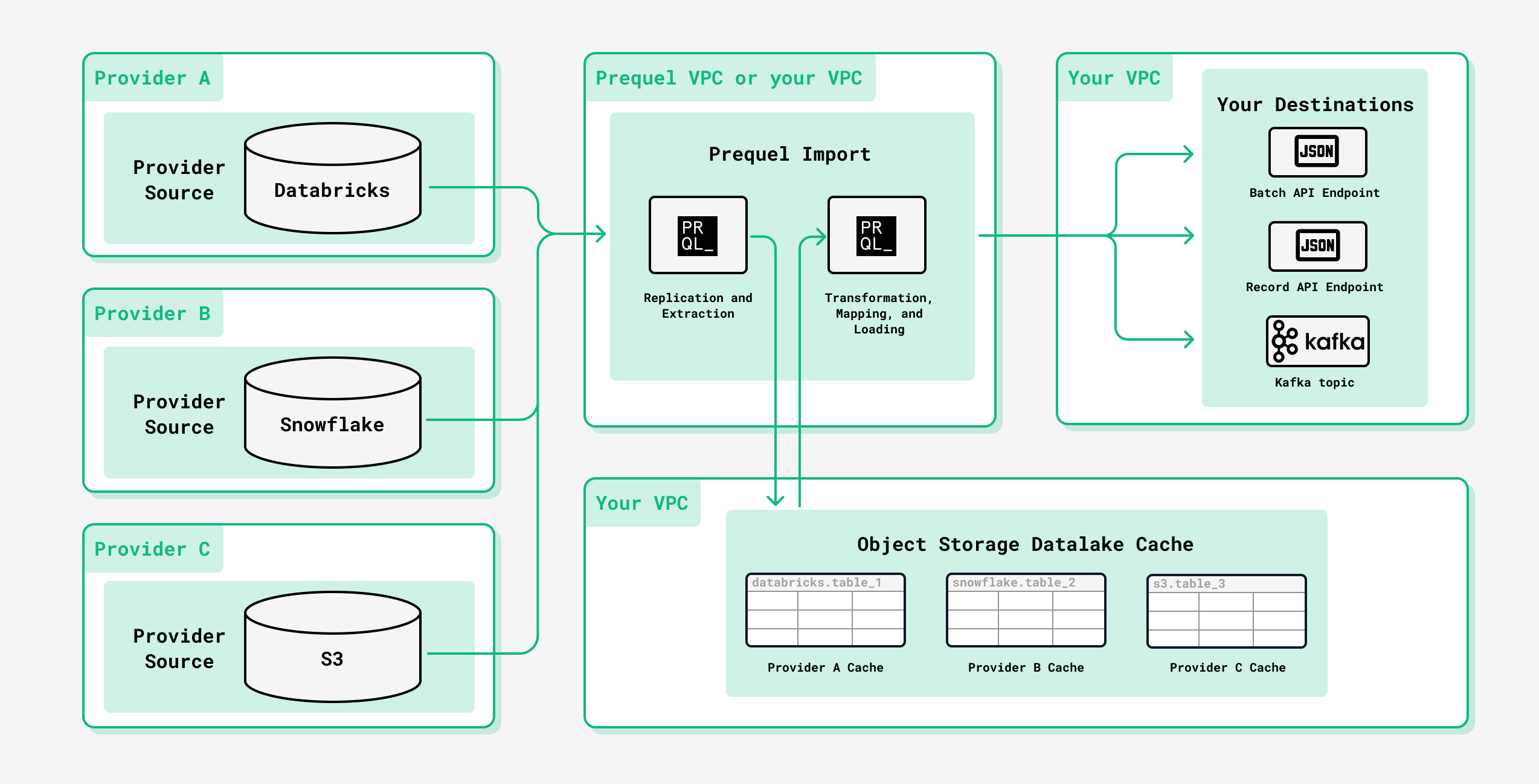
Requirements
To use Prequel Import, you will need to provide an object storage bucket (S3, GCS, or Azure) and implement support for at least one possible endpoint type: spec-compliant API endpoint or Kafka topic.- Record API
- Batch API
- Kafka Topic
Receive individual records as they change via a spec-compliant API endpoint.Learn more about the Record API